모델을 훈련하고 성능을 측정하기 위해서는 전체 데이터를 훈련, 검증 및 테스트 데이터 분할하는 작업이 필요하다. 데이터 분할에 대한 구체적인 내용은 아래 포스팅을 참고하길 바란다. sklearn 패키지는 이러한 작업을 효율적으로 수행하는 train_test_split 함수를 제공하고 있다. 본 포스팅에서는 iris 데이터를 사용하여 데이터 분할에 대한 다양한 예시를 살펴보고자 한다.
2022.11.02 - [Machine Learning/데이터 전처리] - [데이터 전처리] 훈련 및 테스트 데이터 분할
iris 데이터
# 라이브러리 로딩
import pandas as pd
from sklearn.datasets import load_iris
# 데이터 로딩 및 데이터 프레임으로 변환
iris = load_iris()
df = pd.DataFrame(iris['data'], columns = iris['feature_names'])
df['label'] = iris['target']
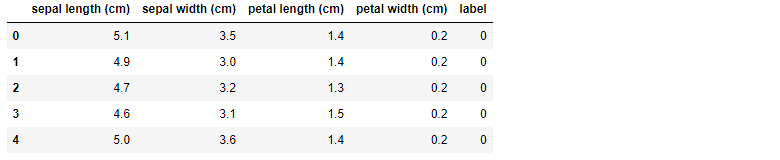
df.head()iris 데이터를 데이터 프레임 형태로 변환하여 출력하면 다음과 같다.
주요 파라미터 개요
- test_size: 테스트 데이터 비율 설정
- random_state: 초기 난수 값 설정(매번 마다 동일한 훈련 및 테스트 데이터 생성)
- shuffle: 랜덤이 아닌 순차적 방식으로 분할할 지 여부를 설정(기본값은 True, 순차적으로 분할할 때 False로 설정)
- stratify: 클래스 라벨(class labels) 비율을 동일하게 유지(분할된 각 데이터에서 특정 클래스 라벨 비율을 동일하게 유지할 때 사용)
데이터 분할(기본값)
일반적으로 머신러닝 모델을 훈련하고 성능을 측정할 때 훈련 데이와 테스트 데이터의 비율을 8:2로 설정한다. 예를 들어, sklearn 패키지에서 테스트 데이터의 비율을 0.2로 설정하면 훈련 데이터의 비율을 0.8로 설정된다. 구체적인 방법은 다음과 같다.
df_train, df_test = train_test_split(df, test_size = 0.2, random_state = 123)
print("전체 데이터 크기:", df.shape)
print("훈련 데이터 크기:", df_train.shape)
print("테스트 데이터 크기:", df_test.shape)전체 데이터와 분할된 데이터의 크기를 확인해보면 설정된 비율과 동일하게 분할된 것을 확인할 수 있다.

다른 방법으로는 전체 데이터를 먼저 특성(Feature)과 라벨(Label)로 분리하고 다음으로 훈련 및 테스트 데이터로 분할하는 방법이 있다.
# 데이터 특성과 라벨 분리
x = df.iloc[:, :4]
y = df['label']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 123)shuffle 설정
일반적으로 데이터를 분할할 때 랜덤 방식을 채택하고 있으나 시계열 데이터처럼 순서를 고려하는 경우에는 랜덤 방식보다 순차적으로 분할하는 방식이 더 효과적이다. sklearn 패키지의 shuffle 인자를 통해 랜덤 혹은 순차적 방식을 선택할 수 있다. 기본값은 랜섬 방식이므로 순차적으로 데이터를 분할할 때 shuffle = False로 설정해야 한다. 구체적인 사용 방법은 다음과 같다.
df_train, df_test = train_test_split(df, test_size = 0.2, shuffle = False, random_state = 123)먼저, 전체 데이티에서 처음 10개 데이터를 추출해서 살펴보자.
df.head(10)
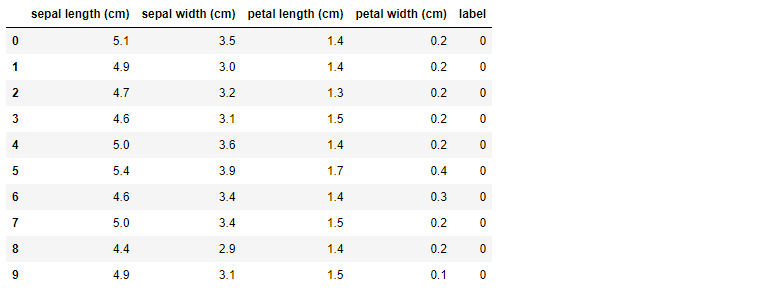
다음으로 순차적 방식을 적용하여 분할된 훈련 데이터를 살펴보면, 전체 테이터에서 처음부터 순차적으로 데이터를 분할한 것을 확인할 수 있다.
df_train.head(10)
stratify 설정
분류 작업에서 훈련 데이터와 테스트 데이터에서 포함된 클래스 라벨 비율이 동일하지 않으면 모델이 편향이 발생할 수 있다. 즉, 클랙스 라벨 비율이 전체 데이터와 분할된 데이터에서 모두 동일한 수준으로 유지하는 것이 중요하다. sklearn 패키지의 stratify 인자를 통해 특정 클래스 라벨를 지정하면 훈련 데이터와 테스트에서 동일한 비율을 유지하도록 지원한다. 구체적인 사용 방법은 다음과 같다.
예를 들어, iris 데이터에서 라벨(label) 값을 훈련 및 테스트 데이터에서 동일한 비율을 유지하도록 설정한다고 가정하자. 먼저 stratify 인자를 지정하기 전에 각 데이터의 라벨 비율을 확인해보자. 먼저, 훈련 데이터에서 각 라벨의 비율은 다음과 같다.
df_train, df_test = train_test_split(df, test_size = 0.2, random_state = 123)
df_train["label"].value_counts()
다음으로, 테스트 데이터에서 각 라벨의 비율은 살펴보면 훈련 데이터와 마찬가지로 각 라벨의 비율이 서로 다르다는 것을 알 수 있다.

sklearn 패키지에서 stratify 인자를 통해 클래스를 지정하고 각 데이터의 클래스 라벨의 비율을 살펴보자. 먼저, 훈련 데이터의 각 라벨 비율을 확인해보자.
df_train, df_test = train_test_split(df, test_size = 0.2, stratify = df["label"], random_state = 123)
df_train["label"].value_counts()
다음으로, 테스트 데이터의 각 라벨의 비율을 살펴보면 훈련 데이터와 동일하게 일정한 비율을 나태냄을 알 수 있다.
df_test["label"].value_counts()
댓글